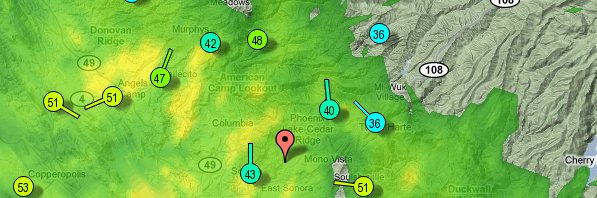
Image: Wunderground Example
The Wunderground.com website offers several creative interfaces to current and historic weather information. One of the more interesting features is the URL-based interface to personal weather stations. As far as I can tell, the Wunderground website only returns hourly data for a single day from personal weather stations... I wanted an entire year's worth of data, so it made sense to abstract the process of fetching a single day's worth of data from a named station into an R function. In this way, it is possible to quickly query the Wunderground website for arbitrary chunks of data. A semi-tested function, along with some examples are posted below. Enjoy!
Example Usage
# be sure to load the function from below first
# get a single day's worth of (hourly) data
w <- wunder_station_daily('KCAANGEL4', as.Date('2011-05-05'))
# get data for a range of dates
library(plyr)
date.range <- seq.Date(from=as.Date('2009-1-01'), to=as.Date('2011-05-06'), by='1 day')
# pre-allocate list
l <- vector(mode='list', length=length(date.range))
# loop over dates, and fetch data
for(i in seq_along(date.range))
{
print(date.range[i])
l[[i]] <- wunder_station_daily('KCAANGEL4', date.range[i])
}
# stack elements of list into DF, filling missing columns with NA
d <- ldply(l)
# save to CSV
write.csv(d, file=gzfile('KCAANGEL4.csv.gz'), row.names=FALSE)
Function Definitions
wunder_station_daily <- function(station, date)
{
base_url <- 'http://www.wunderground.com/weatherstation/WXDailyHistory.asp?'
# parse date
m <- as.integer(format(date, '%m'))
d <- as.integer(format(date, '%d'))
y <- format(date, '%Y')
# compose final url
final_url <- paste(base_url,
'ID=', station,
'&month=', m,
'&day=', d,
'&year=', y,
'&format=1', sep='')
# reading in as raw lines from the web server
# contains <br> tags on every other line
u <- url(final_url)
the_data <- readLines(u)
close(u)
# only keep records with more than 5 rows of data
if(length(the_data) > 5 )
{
# remove the first and last lines
the_data <- the_data[-c(1, length(the_data))]
# remove odd numbers starting from 3 --> end
the_data <- the_data[-seq(3, length(the_data), by=2)]
# extract header and cleanup
the_header <- the_data[1]
the_header <- make.names(strsplit(the_header, ',')[[1]])
# convert to CSV, without header
tC <- textConnection(paste(the_data, collapse='\n'))
the_data <- read.csv(tC, as.is=TRUE, row.names=NULL, header=FALSE, skip=1)
close(tC)
# remove the last column, created by trailing comma
the_data <- the_data[, -ncol(the_data)]
# assign column names
names(the_data) <- the_header
# convert Time column into properly encoded date time
the_data$Time <- as.POSIXct(strptime(the_data$Time, format='%Y-%m-%d %H:%M:%S'))
# remove UTC and software type columns
the_data$DateUTC.br. <- NULL
the_data$SoftwareType <- NULL
# sort and fix rownames
the_data <- the_data[order(the_data$Time), ]
row.names(the_data) <- 1:nrow(the_data)
# done
return(the_data)
}
}