Analysis of SSURGO Data in PostGIS: An Overview
News
It looks like the NCSS has constructed a web-based, SQL interface to their main database. This new tool was recently highlighted in issue 40 of the NCSS Newsletter and looks like a promising new tool with good documentation. A listing of "web services" offered by the NCSS is presented on this page.
Overview
The analysis of SSURGO data is complicated by a series of hierarchical, one-to-many tabular relationships between spatial and attribute data. Understanding the structure of the SSURGO database is critical for correct interpretation and aggregation of soil properties. Before undertaking any SSURGO-based analysis please take some time to become familliar with the details on the product, including intended uses, minimum mapping units sizes, and other important details. In addition, becoming familliar with the SSURGO metadata is a must. The metadata page includes detailed descriptions of table structure, column names and units, as well as important information on the sources of much of the tabular data included in a SSURGO database.
SSURGO data can be downloaded by survey area from The Soil Datamart, with spatial data delivered in shapefile format and attribute data delivered as plain text. Unfortunately, an M.S. Access database template is required to utilize SSURGO attribute data as delivered from the Soil Datamart. For assistance with this procedure please see the NRCS SSURGO page. Using this approach, most analysis of SSURGO must be done survey-by-survey within a GIS environment. For general instructions see this document.
Several online applications allow for simple interaction with the SSURGO database without the need for a GIS or RDBMS knowledge. Some examples include:
- Soil-Web our online interface to CA, AZ, and NV soils data. Example interaction here, here, and here.
- Web Soil Survey provided by the NRCS
- Penn State SoilMap application
An Open Source Approach to SSURGO
We have developed an alternate approach to working with SSURGO data using PostGIS, a spatially-enabled version of the popular and open source relational database management system Postgresql, to store all spatial and tabular data for 138 survey areas. This approach facillitates rapid access, analysis, and aggregation of over half a million soil polygons. SQL (structured query language) is used to directly interact with both soil spatial and attribute data. If other forms of spatial data are imported into PostGIS (such as landcover, climatic data, etc.) nearly all spatial and attribute analysis can be done entirely from PostGIS. A series of examples illustrating common tasks will be presented in the following pages.
General Approach to Working with SSURGO (also outlined in this document) (more ideas on map unit composition)
- Identify the soil properties that are to be included in some analysis
- Decide on the appropriate form of aggregation to be used to summarize horizons
- depth weighted (i.e. to calculate average percent clay through horizons)
- top 1m (i.e. to summarize shrink-swell capacity of the topsoil)
- top horizon (i.e. to summarize surface organic carbon)
- profile sum (i.e. to calculate total water holding capacity)
- most limiting (i.e. to calculate the most limiting hydraulic conductivity within the soil profile)
- Aggregate horizon data: after filtering NULL values and weights
- Decide on the appropriate form of aggregation to be used to summarize components
- component percent weighted (i.e. this will include information from each component, weighted by their estimated percentage of the entire map unit)
- largest component (i.e. this usually result in the selection of the 'dominant' component, however when there are multuple components with the same estimated percentage ties will occur)
- major component flag (i.e. components flagged as a 'major component' by the NRCS represent dominant soil types within a map unit. note that there are sometimes multiple components flagged as 'major components'.)
- dominant condition (i.e. this is usually used for categorical data like hydric conditions. aggregation is performed by selecting the most frequent condition within a map unit)
- Aggregation of component data: after filtering NULL values and weights
- join the above aggregated data (2x aggregation process for horizon data) to the map unit polygons
- See the diagram at the bottom of this page for a graphical summary
 Notes on the Format of SSURGO
Notes on the Format of SSURGO
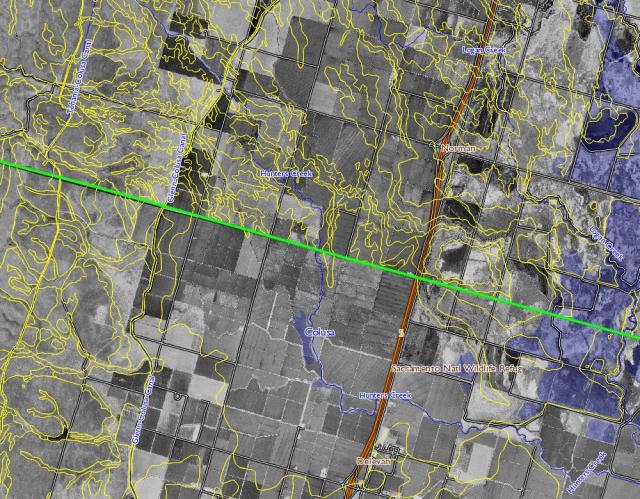
- Adjacent surveys may have been composed by different individuals, and may be of widely different vintages. Any given survey must comply with basic standards, but older surveys reflect a more generalized approach than more modern surveys. The figure to the right illustrates such differences.
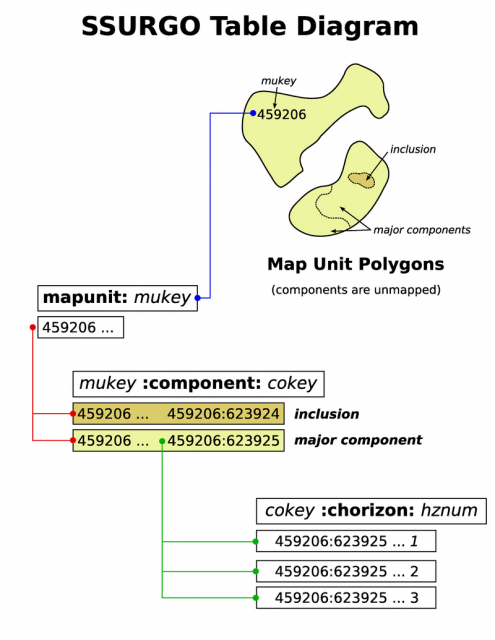
- Polygons represent a repeating pattern of legend entries: groups of map-able soil concepts called map units
- Map unit data is stored in the mapunit table, and is referenced by the field mukey
- Pre-aggregated map unit data is stored in the muaggatt table, and is referenced by the field mukey
- Map units are comprised of multiple, unmapped soil types called 'components'
- Component data is stored in the component table, and is referenced by the field cokey
- Soil components (or soil type) are associated with multiple horizons
- Horizon data is stored in the chorizon table, and is referenced by the field cokey
- Since there is a 1:many:many (mapunit:component:horizon) relationship between spatial and horizon-level soil property data two aggregation steps are required in order to produce a thematic map
- This diagram illustrates the hierarchy of scales involved in soil survey information.