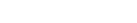Cluster Analysis 1: finding groups in a randomly generated 2-dimensional dataset
Examples based on a random data set (see example code below), illustrating some of the differences between the K-means and C-means clustering methods as implemented in R. Next time an example with soil profile data collected from the Pinnacles National Monument soil survey efforts. An online version of the PINN soil survey will be available soon here.
Articles:
- Quick tutorial on clustering approaches
- Lecture on K-means algorithm
- Notes on hierarchical clustering
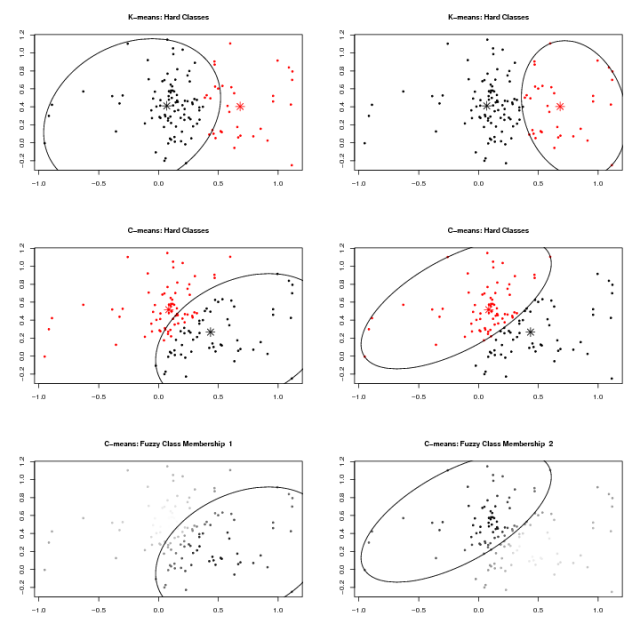 Figure 1. Two class example |
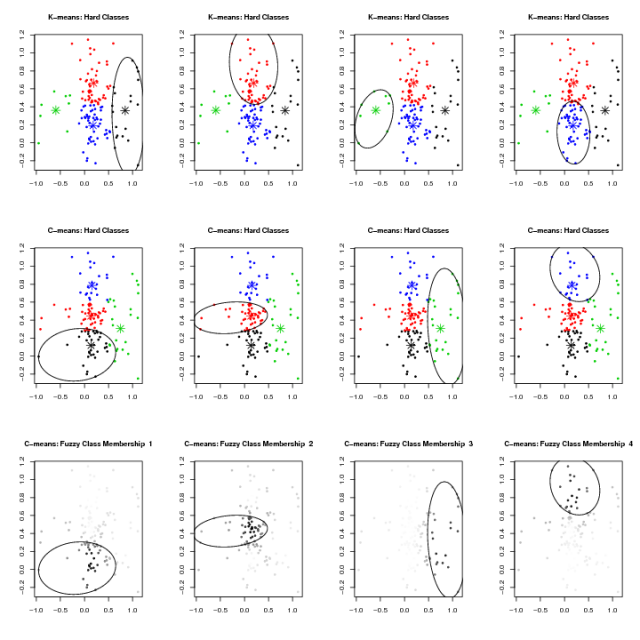 Figure 2: Four class example |
 Figure 3: 2-way fuzzy membership |
Example in R:
## load required packages:
require(cluster)
require(e1071)
## make a dateset with 5 populations
x <- matrix( c(
rnorm(50, mean=.3, sd=.5),
rnorm(50, mean=.16, sd=.1),
rnorm(50, mean=.4, sd=.3),
rnorm(50, mean=.6, sd=.2),
rnorm(50, mean=.2, sd=.2)
), ncol=2)
## load function membership() : see attached file at bottom of page
source('cluster_demo_function.R')
## run an example with 2, then 4 classes: See Figures 1 and 2
membership(x,2)
membership(x,4)
## two-way fuzzy membership illustrated with color: See Figure 3
## display 2-way fuzzy membership
plot(x, main="C-means: 2-way Fuzzy Membership", type="n", xlab="Variable 1", ylab="Variable 2")
points(cc$centers, col = c("red", "blue"), pch = 8, cex=2)
points(x, col = rgb(cc$membership[,1], 0 ,cc$membership[,2]) , cex=0.5, pch=16)